前言
如今 AI 编程的“及格线”不断上涨。真正拉开差距的不是会不会写代码,而是能不能把 AI 当成杠杆:在认知有缺口时,依然能快速把需求推到可验证、可交付的结果。
这篇文章复盘一次真实实践:对前端复杂 Excel(经开源组件 LuckySheet 转换得到的 JSON)做内容解析,最终抽取成 KV,再进一步转成 Markdown 存储。
这次实践我做了什么
工具使用一:代码解释 → 快速补齐上下文
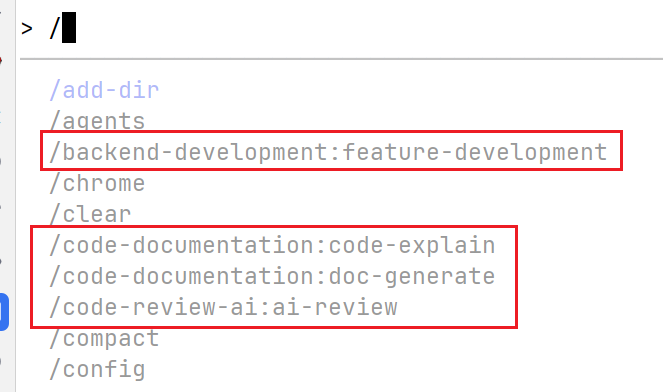
Claude Code 工具:https://github.com/wshobson/agents/ 。我安装了下图所示的几个能力,其中“代码解释”对本次需求帮助很大:先把项目里已有的初版实现讲清楚,让我能快速理解代码逻辑和数据流。
工具使用二:托管式编码 → 但模型能力有上限
利用 ccswitch 进行全局托管Claude Code 工具密钥编码,结合我期望的提示词 + 上述梳理的代码逻辑,让 AI 在现有项目约束下写实现。
问题是:当底层模型的编码能力不足时,多轮对话会陷入“看起来在进展、但没有真正收敛”的状态——产出缺少可验证性,边界条件也容易漏。
工具使用三:换更强的编码模型 + 用研究能力补“具体知识”
在上述方案效果一般的情况下,我又使用 Codex(GPT-5.2-codex)做进一步修改,但依然没达到预期。最终我引入 Gemini 的 Deep Research:先用搜索能力把“领域具体知识”和“可执行的约束”补齐,再回到编码模型上落地。
提示词展示(节选):
Role
You are a Senior Java Backend Engineer specializing in Data Engineering and Unstructured Text Parsing. You are an expert in handling sparse matrices and heuristic algorithms.
Objective
Create a pure Java implementation to parse "LuckySheet JSON" data into structured tables. The input JSON represents an Excel sheet that may contain multiple distinct tables stacked vertically. The parser must identify these tables, handle merged cells correctly, and extract data without using Apache POI or calling external AI APIs.
Input Data Specification
The input is a JSON String representing a LuckySheet object. Key fields:
celldata: A List of objects representing sparse cell data.- Schema:
[{ "r": int, "c": int, "v": { "v": rawValue, "m": displayValue, "bg": "#hexColor", "bl": 1 (if bold) } }] - Note: Only non-empty cells exist in this list.
- Schema:
config: An Object containing metadata.merge: A Map defining merged cells. Key format"row_col", Value{ "r": int, "c": int, "rs": int, "cs": int }.
Critical Business Rules (Must Implement)
Rule 1: Virtual Grid & Flattening (The "RAG Context" Rule)
Before parsing, you must reconstruct the sparse celldata into a dense 2D grid structure (e.g., Map<Integer, Map<Integer, Cell>>).
- CRITICAL: You must process
config.merge. If a cell (2,0) hasrs: 2(rowspan 2), it means the cell physically exists at (2,0) but logically covers (3,0). - ACTION: You must copy the value and attributes of the anchor cell (2,0) into the virtual position (3,0). This ensures that when we read Row 3, column 0, we get the value "Basic Information" instead of null. This is vital for downstream RAG retrieval.
Rule 2: Heuristic Table Segmentation (The "Split" Rule)
The sheet contains multiple tables separated visually. You must implement a segmentation algorithm List<TableBlock> detectTables(VirtualGrid grid) based on these heuristics:
- The Empty Gap: A row (or consecutive rows) that contains NO data acts as a separator.
- The Title Row: A row containing a single cell with a
colspan(cs) > 5 (or spanning > 80% of data width) signifies the start of a new table section. Use this row's value as thetableName. - The Header Color Signal: In the provided data, table headers have a specific background color (e.g.,
bgis not null, specifically looking for blue-ish colors like#0070C0). If rowihas this background color and rowi-1does not,row iimplies the start of a new table header.
Rule 3: Header Resolution
For each detected TableBlock:
- Scan the top 5 rows.
- Score each row to find the "Header Row":
- +Score for background color present.
- +Score for Bold text (
bl: 1). - +Score for String content density.
- Rows above the Header Row are treated as Metadata/Title.
- Rows below the Header Row are Data.
Implementation Requirements
- Library: Use
com.fasterxml.jackson(Jackson) or Gson for JSON parsing. Do NOT use Apache POI. - Class Structure:
LuckySheetParser: Main service class.VirtualGrid: Helper class to handle sparse-to-dense conversion and merge flattening.TableBlock: Represents a row range[start, end].TableData: The final output POJO containingtableName(String) androws(List<Map<String, String>>).
- Robustness: Handle
nullvalues safely. The grid may have gaps.
反思与总结
- 熟悉工具使用能力边界。
- 对于具体使用哪种工具进行使用需要熟悉不然很难解决这个问题,例如在EXCEL的Java领域目前做的比较好的是Apache POI,从这个角度出发让AI进一步扩展。
纳瓦尔视角:下一步如何“更进一步”
纳瓦尔常讲的几个关键词可以直接映射到 AI 协作编程上:杠杆、复利、具体知识、判断力。你这次已经获得“AI 让你更快”的一次性收益;下一步要做的是把收益变成可复用、可复制、可迭代的系统。
1) 把一次性对话变成“可复用资产”(复利)
这次你写了很强的提示词,但它仍然偏“一次性”。更进一步的做法是把它沉淀成可复用资产,让下次遇到类似解析/ETL/非结构化抽取时直接复用:
- 约束模板:输入/输出、禁止使用的库、性能约束、边界场景(空行分割、标题行、表头颜色、合并单元格等)。
- 样例集:抽 5~10 份真实 LuckySheet JSON(脱敏)+ 期望输出(KV/MD),当作回归用例。
- 评估方式:把“看起来对”变成“跑一下就知道对不对”(单元测试/快照对比/统计缺失率)。
AI 真正擅长“写很多候选实现”,但你要让它在一个明确的评估框架里被筛选——资产越清晰,越能复利。
2) 用“可验证性”替代“多轮对话”
你遇到的卡点,本质是:没有足够快的验证回路,导致对话变长、成本变高。
把工作流改成:
- 先定义验收(输入 JSON 片段 → 输出 KV/MD 的关键断言)
- 让 AI 先写测试(或至少写断言清单)
- 再写实现
- 用失败结果喂回去迭代
这样 AI 每一轮都在“收敛到可运行的正确性”,而不是“收敛到一段看起来合理的解释”。
3) 工具杠杆:选择 > 努力
你已经观察到不同工具/模型的差异。纳瓦尔式的做法是把它当成“杠杆选择题”:
- 读代码/理清上下文:选择更擅长理解与总结的工具,让你更快获得“局部判断力”。
- 写代码/修 bug:选择更强的编码模型 + 更严格的约束 + 更短的反馈回路。
- 补具体知识:在你不熟的领域,先用研究能力把“行业默认解”和“典型坑”搜出来,再编码。
更进一步:不要把“换模型”当成救火,而是把它固化成流程中的一个决策点(什么时候该换、换到哪、以什么信号判断)。
4) 具体知识与判断力:AI 时代程序员的护城河
AI 可以替你写实现,但不能替你负责。最终决定“该怎么做”的,是你的判断力。
在这类 Excel/LuckySheet 解析问题上,判断力来自两块:
- 具体知识:合并单元格的语义、稀疏矩阵重建、表格分块的启发式、异常数据的处理方式。
- 工程判断:什么时候用启发式、什么时候必须引入显式规则;哪些错误可容忍、哪些会污染下游(例如 RAG/检索)。
更进一步的成长方向是:把这些判断固化为“你自己的解析框架/经验库”,让 AI 成为你框架里的执行器,而不是让你成为 AI 的校对员。
评论功能
当前站点为 GitHub Pages 镜像版本,不支持评论功能。
如需发表评论,请访问主域名版本:
🚀 前往 主域名 版本评论